
1) Connection to the machine
You must use ssh on : occigen.cines.fr
ssh <mon_login>@occigen.cines.fr
The operating system is of the linux type based on the BullX SCS (Redhat) software suite.
The cluster includes several connection nodes for users. When the connection is established, the user is on one of these nodes. The assignment of connections is based on the availability of login nodes. It is possible that two simultaneous connections may end up on two different login nodes.
2) Software environment : modules
CINES provide lot of softwares on his clusters, and often, various versions of each software. In order to further prevent conflicts between differents versions, you need to define a specific environement for each software.
The available software can be viewed or loaded via the following commands:
module avail |
display the list of all the environments available |
module load |
load a librarie or a software in your environment |
module list |
display the list of your current environment |
module purge |
remove one librarie or software from your environement |
module show |
show the content of a module |
3) Job submission environment (SLURM)
The compute nodes of the Occigen machine can be used in two modes :
- Exclusive mode
- Shared mode
a) Jobs in « EXCLUSIVE » mode
After the Occigen extension went into production in February 2017, which consists of nodes with Broadwell processors, work was submitted on two distinct partitions: the Haswell processor part (24 cores) and the Broadwell processor part (28 cores).
Since spring 2018, we have been offering more flexibility, allowing you to request either both architectures at the same time or one or the other without specifying which one. The table below summarizes the different possibilities and the SLURM guideline associated with each case.
| Type of job | Processor choice | Directive SLURM |
| Code OpenMP |
Haswell node only
|
--constraint=HSW24 |
|
Broadwell node only
|
--constraint=BDW28 |
|
|
Parallel code MPI / Hybrid code |
Haswell node only
|
--constraint=HSW24 |
|
Broadwell node only
|
--constraint=BDW28 |
|
|
Precise configuration ofx Haswell nodes and yBroadwell nodes
|
--constraint="[HSW24*x&BDW28*y]" |
|
|
Haswell or Broadwell nodes regardless (HSW24 and BDW28 can be mixed)
|
--constraint=HSW24|BDW28 |
|
|
All nodes of the same type, Haswell or Broadwell depending on availability
|
--constraint=[HSW24|BDW28] |
You will find batch submission script templates describing all these cases in the CINES gitlab in the following directory :
b) Jobs in « SHARED » mode
In shared mode, several jobs can run simultaneously in one node. A technical mechanism prevents jobs from interpenetrating each other, there can be no overwriting of memory areas, nor “theft” of CPU cycles.
By default, all jobs thatrequire less than 24 cores will be in shared mode.
All nodes in the shared partition have 128 GB of memory.
Jobs with a demand greater than 23 cores are not affectedby the shared mode, nor are jobs that explicitly request the exclusive mode.
c) Commands
This table provides useful commands for submitting work.
| Action | command |
| Submit a job |
sbatch script_soumission.slurm |
| List all the jobs |
squeue |
| List only your jobs |
squeue –u <login> |
| Display caracteristics of a job |
scontrol show job |
| Forecasting the time of a work shift (may vary …) |
squeue –start –job <job_id> |
| Forecasting the schedule for the passage of your own work |
squeue –u <login> --start |
| Cancel a job |
scancel <job_id> |
Submitting a job HTC
These tasks correspond to command lines containing sequential executable (serial) and their argument(s) if necessary. The executable is called pserie_lb.
| Variable name | value |
| $SLURM_JOB_ID | Job Identification |
| $SLURM_JOB_NAME | Job name (specified by “#SBATCH -J”) |
| $SLURM_SUBMIT_DIR | Name of the initial directory (in which the sbatchcommand was launched) |
| $SLURM_NTASKS | Number of job MPI processes |
e) Common SBATCH options
In the SLURM script to give indications on the resources it is possible to use the following directives:
- To indicate the number of physical nodes of the machine:
#SBATCH --nodes=W
- To indicate the total number of MPI threads that will run on nodes containing 48 or 56 hyperthreaded cores, use the following directive:
#SBATCH --ntasks=X
- To indicate for OpenMP codes how many threads will be affected per machine core:
#SBATCH --threads-per-core=Y
- To indicate the amount of memory you want in a node (cannot exceed the total memory of the node, 64 GB or 128 GB):
#SBATCH --mem=Z
- Finally, this directive is an indicator that specifies that you do not want to share the node on which your job will run with another job:
#SBATCH --exclusive
In a shared node, each job can consume all or part of the node’s memory.
Or, a job may need to consume a lot more memory.
In this second case, the job manager will not place a new job in this node, until the memory is freed. For this example, job J1 will be billed for 1 core, while job J2 will be billed for 5 cores (maximum between the number of cores requested (–ntasks=1) and its memory size divided by 5). On this simplified example, the maximum is 5, so it will be charged 5 cores.
Here are some examples of using these parameters
Example1:
#SBATCH –nodes=1# A single node #SBATCH –ntasks=48# As many threads as desired #SBATCH –threads-per-core=2 # Number of threads per physical core: i.e. a sub-multiple of the number of tasks >–encoded_tag_closed here we reserve 24 physical cores
If you do not reserve all the core and/or memory resources, another job may start on the node using the remaining resources.
It is possible to impose the “dedicated node” mode using the directive:
#SBATCH –exclusive
If no memory request is specifiedby the user in the submission script, the job running on a shared node is assigned a memory limit of 1 GB per job.
The default value is deliberately low to encourage users to define their needs. Here is the directive to use to express its memory requirement:
#SBATCH –mem=4000 # 4GB guaranteed memory per node
4) Submitting a job HTC
PSERIE is a tool that allows you to perform sequential tasks or jobs within an MPI job These tasks correspond to command lines containing sequential executable (serial) and their argument(s) if necessary. The executable is called pserie_lb.
a) Description
When using this version, the MPI process (or rank) #0 distributes the tasks to be performed to other MPI processes. It does not execute any commands. The other processes are each assigned a task. Once a process has completed one of its tasks, rank 0 assigns it a task that has not yet been completed. This distribution is performed as long as tasks have not been executed (as long as command lines of the input file have not been processed). There is no order of execution of tasks; the first MPI process that is ready to receive a task will be assigned the first available (not executed) task from the list in the input file. The input file can contain more command lines than the number of processes.

b) Utilization
To use this tool, three modules must be loaded : intel/17.0, openmpi/intel/2.0.1 and pserie. Pserie requires an input file where the commands to be executed are located.
Example of input file input.dat :
—————————————
./mon_exécutable mon_argument_égal_à_paramètre_1
./mon_exécutable mon_argument_égal_à_paramètre_2
./mon_exécutable mon_argument_égal_à_paramètre_3
./mon_exécutable mon_argument_égal_à_paramètre_4
./mon_exécutable mon_argument_égal_à_paramètre_5
...
c) Example of script SLURM :
#!/bin/bash
#SBATCH -J job_name
#SBATCH --nodes=2
#SBATCH --ntasks=48
#SBATCH --constraint=HSW24
#SBATCH --time=00:30:00
module purge
module load intel/17.0
module load openmpi/intel/2.0.1
module load pserie
srun -n $SLURM_NTASKS pserie_lb < input.dat
Note: There is an example of use with the associated slurm script under /opt/software/occigen/tools/pserie/0.1/intel/17.0/openmpi/intel/2.0.1/example with the input file named fdr.dat which contains the list of commands to execute. The commands in this file include simple echo and sleep commands.
Overtime calculation hours (+25% initial staffing)
-
As soon as the consumption of a project exceeds 125% of its initial allocation of hours, this project is blocked and no member can submit any more work.
-
A priority system makes it possible to manage the execution of work on the machine in the most equitable way possible between projects. This system takes into account various parameters, including in particular the initial allocation of hours and the consumption of hours spent (the effective recognition decreases exponentially over time, with a half-life of 14 days).
-
A project that has under-consumed in the recent past (i.e. the last days/weeks), has a high priority for the execution of its work.
-
A project that has over-consumed in the recent past (i.e. the last days/weeks) is not blocked, it can continue to run but with a low priority and can therefore benefit from the cycles available on the target machine in case of low load.
-
-
This priority system maximizes the effective use of CPU cycles by:
-
Encouraging projects to use their hours regularly throughout the year to maximize hours with a high priority of execution
-
Allowing projects, in the event of under-utilisation of the machine, either to catch up on a consumption delay or to get ahead despite a low priority of execution, with no limit on hours other than that of 125% of their initial allocation of hours.
-
6) Environment variables
- Make the best use of the machine’s resources (in its Tier1 specificity).
- Fairly arbitrate competing demands for resources.
Two ways of using resources:
- “debug/dev” and “production” are defined with a higher priority assigned to the first. The mode is determined based on resource demand.
- Jobs are limited by defaultto 24h and 700 nodes. (optimal filling of the machine and taking into account the MTBF vs production operations) limits that can be adjusted according to needs, for this contact us.
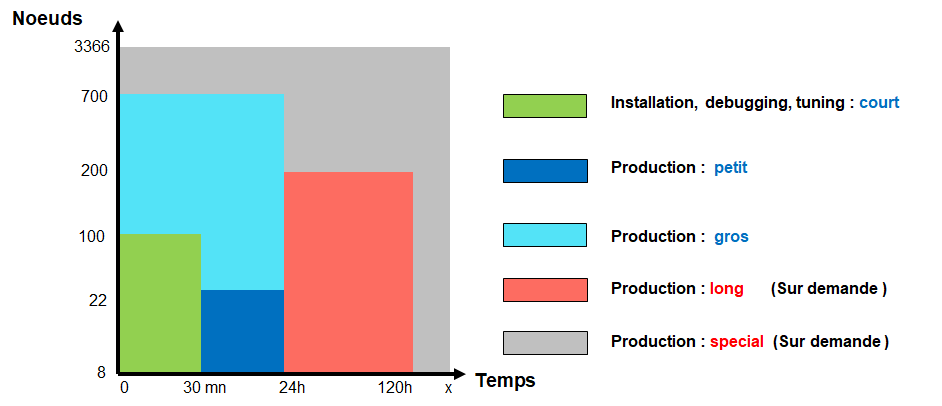
- The priority increases with the waiting time (cf: “priority age factor“in the Slurm documentation)
- The number of nodes requested has no impact in the priority calculation
- The recent use of resources is taken into account in the calculation of the priority: the less a project has consumed cores.hoursrecently, the higher will be the priority of its works
Resources can be mobilized in a TETRIS-type management approach (Time x Nodes ): a waiting job can start before a higher-priority job as long as it does not delay the moment when the resources it is waiting for become available ( cores.hours and number of nodes)
For the same number of nodes requested, the shorter duration of use has a higher priority.
- the number of nodes: #SBATCH –nodes=xxx
- execution time : #SBATCH –time=xx:xx:xx
- the type of processor : #SBATCH –constraint=”xxxx”
- It is preferable to specify a machine residence timeclose to the need (with a reasonable margin), to take advantage of the “backfill” mechanism
- The load on the machine may induce a significant increase in waiting times.
- The machine has two partitions with different processors (Haswell and Broadwell). It is common for the pressure on each partition to be different. To consult the state of this load, you can use the etat_machine command which will indicate the partition with the least load (you can also consult the load via the reser site)
- The internal technical aspects specific to the administration of SLURM (QoS, Partitions, …) are transparent for the users, who do not have to take them into consideration to submit jobs
7) Common mistakes :
When a job exceeds its memory request, the process responsible for it is killed by SLURM and the job stopped. Other jobs active on this node will not be impacted. If a job causes a “memory overflow”, it is processed at the Linux kernel level and neither the node nor the other jobs should be affected.
An error message then appears in the output file:
…
/SLURM/job919521/slurm_script: line 33: 30391 Killed /home/user/TEST/memslurmstepd: Exceeded step memory limit at some point.
…
Shared jobs will also be taken into account in the blocking process in case of over-occupation of /home and /scratch storage spaces. Shared jobs will be assigned to partitions whose names will be suffixed bys. Example:BLOCKED_home_s for a shared job blocked for exceeding a quota on /home.
To notice that a job is started in shared mode, just look at the partition in which it is assigned:
login@occigen54:~/TEST$ squeue -u login JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON) 919914 shared TEST_SHA login R 0:04 1 occigen3100
We see that the job 919914 runs in the sharedpartition.
To know the status of shared nodes, run the command : sinfo -p shared -o « %.15n %.8T %.8m %.8O %.8z %.14C »
login@occigen54:~/TEST$ sinfo -p shared -o “%.15n %.8T %.8m %.8O %.8z %.14C” HOSTNAMES STATE MEMORY CPU_LOAD S:C:T CPUS(A/I/O/T) occigen3100 mixed 128000 0.00 2:12:2 24/24/0/48 occigen3101 idle 128000 0.00 2:12:2 0/48/0/48 occigen3102 idle 128000 0.00 2:12:2 0/48/0/48 occigen3103 idle 128000 0.01 2:12:2 0/48/0/48 occigen3104 idle 128000 0.01 2:12:2 0/48/0/48 occigen3105 idle 128000 0.00 2:12:2 0/48/0/48
We see that there are (at the time of the order) six nodes in the “shared” partition (occigen3100 to 3105).
The occigen3100 node in the “mixed” state already contains one or more jobs.
The node was occupied on half of its hearts (24/24/0/48). 24 allocated cores, 24 idle cores, 0 in the “other” state, and a maximum of 48 cores per node.