
Focus on scientific data and archiving problems.
There is a strong link between the computing power of an institution and the amount of data it consumes and produces. By offering to the French scientific community, a power of 267 Tflop , CINES must manage a huge amount of scientific data.
Recognizing the importance of this data, and beyond simple storage, CINES remains committed to consolidate its expertise on issues inherent in the life cycle of this data. Thus it may propose to the scientific community tools for their valorization and preservation.
This expertise is based on the historical management of scientific data related to its supercomputing mission , his involvement at the EUDAT and his long term preservation mission.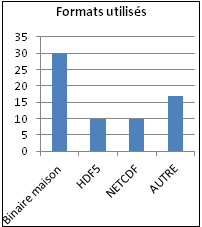
To collect additional information in 2011, we launched a survey with 150 French laboratories using our supercomputeur for their data. All these elements allow us to offer an overview of scientific data in France and Europe.
Whether at the level of consumption, production or operation, the life cycle of scientific data involves scientific libraries, software applications or sometimes “house” which often determines format. A majority of projects using supercomputing have output binary format data . ASCII and text files are used in a third of projects to complement data . The data in HDF5 and NETCDF are also present. Other formats are rarely used as FITS, Grib, CGNS.
It is not strange that a common problem is the standardization of data.
The Interest is sharing data during works. A majority of the projects need to share their data, but in priority in a limited circle of collaborators known. Willingness to share with the entire scientific community is rare or it could be done in a second time, eg after publication.
Data are not exploitable from software to another, it is necessary to convert them systematically using pivot formats, specified and sufficiently generic to be understandable and interoperable within a same community while answering to constraints of a problem often linked to a discipline.
Panorama of the most popular formats:
HDF5, NetCDF are open formats , royalty-free and very general. They are self-describing to the extent that data and metadata are contained in the file itself. They are designed to hold and manipulate matrices as a mesh …
FITS is an open format, royalty-free adapted to scientifics images, it provides advanced description of the image using metadata contained in its header in ASCII format. Each data block can then be described by a couple attribute / value. A number of attributes is available in FITS format, apart from this, the user has the option to define their own.
Scientific data are usually, with a certain complexity, phenomena very accurate. Any description has its limits and if it has not been maturely reflected, it may appear a risk of loss of knowledge in case of departure of a person for example. It is very important to make a description of at least two levels to mitigate this risk.
Syntactic description allows to know the organization of data in the file. (eg primitive types, size, position in a table … etc..). This information is usually part of the header files and primarily for computer systems which exploit them.
A semantic description will provide information on the correspondence between the data and the meaning attributed to it. Such value corresponds to a temperature, a pressure… This metadata can also be directly contained in the data file or described in an external file.
What to do to ensure that the data will be used by a third party?
It does not mean to impose a standard format or a laborious process data description to a lab that does not have the means to implement them but to make sensitive and to lead producers to a good risk management and to consequences of the loss of operability of their data.
It may indeed be helpful to ask a number of questions about the life cycle of its data:
- For what purpose has been produced this data? (Sharing with the wider community, or only for a specific job in the laboratory?)
- Who are the recipients of the data and have they a knowledge base and tools sufficient to use this data? (eg members of the laboratory or all of the scientists working on this thematic will they be able to understand what binary file?)
- How long this data is it relevant, the backup level is it to the measure of the cost of production …
Depending on the responses, it appears useful, even essential to engage , as an exemple, a home format migration without description to a standard format and if it is not sufficient to associate a set of metadata understood by recipients. Note here that our survey reveals that 40% of the binary files do not pose a priori migrating problems to a standard format like HDF5 or NetCDF.
Note however that binary format with a good description of its contents remain easily readable by a third and perennial in time. Tool BEST is a solution proposed by CNES to describe binary files whether at the syntactic level with the EAST language ,or semantic level with internal NASA standard ( DEDSL) which now enjoyed an international reputation.
The communities of researchers are very different, laboratories are highly specialized in their domain of activity and the description of the data is not necessarily a priority. However, data is a representation of a basic reality, it is not self descriptive and does not has necessarily an obvious sense. The purpose of metadata (metadata: beside, beyond, encompassing) is to add a descriptive level relevant enough to allow its exploitation and its sharing in the best conditions.
Most laboratories do not have standard for metadata sets. They describe data mainly using references to text files, notes, publications, theses, web pages, source code, simulation parameters, or even just using a mnemonic naming system files.
Communication of information, collaborative work is essential in the open world which is ours now. Also, it is important that laboratories, scientific communities that have a common problem will be federated around these challenges in order to bring out the means and common repositories able to ensure readability and a sufficient understanding of the data they produce.
The main goal is simple: to describe the data so that they are usable by all people to whom they are intended.
To assess the importance of this, imagine the consequences if there were no reference language ie English to describe scientific articles!
To achieve this, actions at several levels are set up:
Organizational find interlocutors, articulate exchanges depending on the qualifications.
Computing implement infrastructure software, hardware, protocols to process metadata itself.
Archivistics find the standards and exchange formats relevant in the domain, to allow the information to emerge unscathed from the ravages of time.
Methodological It is important to identify the recipients of the data (target community) and measure their ability to understand this data (knowledge base). Then it is necessary to establish a set of information representation which will constitute a semantic link between the data and the community.